The 19 January 2019 issue of The Economist (pages 76-77) contains a very interesting article under the title of “Extending the genetic code: Adding new DNA letters make novel proteins possible: One such, a cancer drug, is now in development.” Here are some of my notes from it, the first two paragraphs being a first attempt (heavily dependent at this stage on the text of the article) to begin writing (and understanding) my own depiction, for use elsewhere, of the nature and function of RNA and DNA:
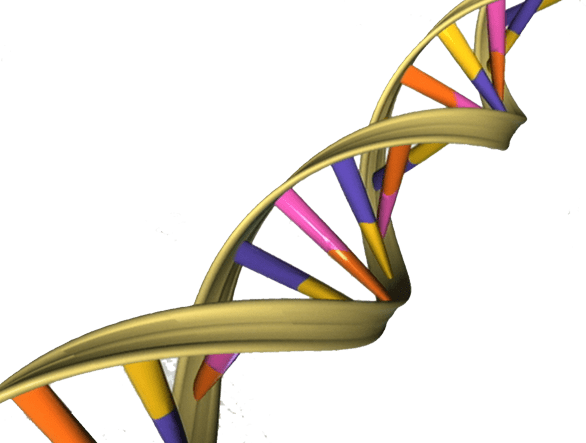
Virtually every terrestrial organism relies on a quartet of genetic bases: A (adenine), C (cytosine), T (thymine), and G (guanine). These all fit together in pairs inside a molecule of deoxyribonucleic acid, or DNA, a self-replicating material present in nearly all living cells as the main constituent of chromosomes and the carrier of genetic information. Along its double strands, A matches T and C matches G.
In the typical cell, the production of protein operates something like industrial manufacturing. First, DNA is transcribed into ribonucleic acid (RNA), which is also a string of bases but which is single-stranded rather than a double strand. The bases of this RNA are then “read,” by a molecular machine called a “ribosome,” in groups of three. These groups are called “codons.” Of the 64 possible codons, 61 correspond to one of 20 versions of a type of molecule that’s called an amino acid. (The other three act as “stop” signals.) When a ribosome reads a codon, it links it with another molecule carrying the appropriate amino acid, and the resulting amino acid string is a protein.
Dr. Floyd Romesberg and his laboratory at Scripps Research in La Jolla, California, have now created a genetic alphabet that uses six chemical letters (A, C, T, G, X, and Y) instead of the normal four. In principle, at least, the two new letters permit an additional 152 potential codons, atop the already existing 64.
What is the point of this? Dr. Romesberg and his associates hope, first, to improve the effectiveness of the tumor-fighting (but thus far underperforming) drug interleukin-2. (Read the article to see why.)
To steady the nerves of “those who worry about genetically modified organisms escaping from the lap,” the article in The Economist concludes by pointing out that, “Without a steady supply of X and Y, any escapee would not get far in the wild.”