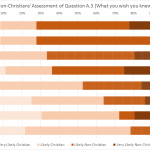
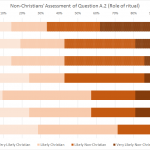
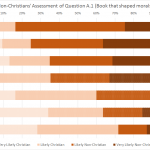
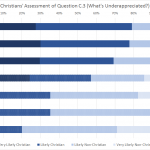
I’m a little disappointed in the commentariat for not bitching me out when I showed you the winners and losers in the Christian and Atheist rounds of the Turing Test without ponying up sample size numbers. This year, each entry had its own survey link, so the number of respondents was not constant across a round. A fairly predictable trend emerged.

Note: This isn’t the total number of respondents, it’s the N for the number of self-declared atheists judging the first round and self-declared Christians judging the Christian round. Looking at how well people do at spotting fakes in the group they don’t belong to is interesting, but I exclude those people from the figures that identify the winners.
Unsurprisingly, there’s a big drop off as people got tired of reading and judging entries. The difference between participation in the Christian and Atheist round is mainly a function of how many bloggers in each category I got to promote the test to their readers. I’ll probably do this again next year, and I’m wondering if readers have any advice on tweaking the methodology to avoid this precipitous drop in response rates.
Making people answer all the questions at once is a pretty big commitment, so it depresses response rates across the board. I got lucky last year, in that Andrew Sullivan linked the test, so my click throughs were high enough to be able to bleed off a lot of people and still have good numbers. I can’t count on huge links like that when I design my methodology. The big upside of the all-in-one survey is that I can compute each participant’s accuracy and then maybe compare whether converts and deconverts did better than people who have stuck to only one philosophy.
Ideally, I’d be able to randomize the order that people answered in, but that seems pretty impractical. And that set-up would make it awfully hard to read a couple, vote, and then take a break before you got burned out. Anything that would let you store answers as you go, and then return to them later would be beyond my webdesign/database skills at present. (For last year’s all-in-one survey, I recommended people keep a paper and pen by their computer).
Another way to track responses across separate surveys would be to get people to generate userids that wouldn’t give too much data away. (Think last four digits of phone number followed my MMDD birthday). Something easy for you to remember and enter on each individual survey, not too likely to be duplicated, and not that dangerous to share with me.
I’d be interested in your thoughts on the tradeoffs of these approaches and advice on tweaks. Mind you, I’d really love for next year to be the round we try out chat logs instead of essays, so a more radical overhaul may be necessary.